简谈布谷鸟过滤器:它是比布隆过滤器更好的选择吗?
其实我一直想研究一下布谷鸟过滤器,但苦于找不到一个合适的契机。真正促使我查找布谷鸟过滤器相关的资料并决定写这篇博客的原因,还要追溯到半个月之前欢聚时代的一场面试。
面试官:“你的xxxxx功能用到了布隆过滤器,但假如是xxxx从数据库中删掉了,布隆过滤器里面的数据怎么处理?”
我:“如果是这样的话,因为布隆过滤器是无法删除数据的,所以只能在删数据之前做一个特判,然后拿一个Set之类的数据类型存起来……其实还有一个更好的解决方案,就是布谷鸟过滤器,它可以实现元素的删除,解决了布隆过滤器无法删除元素的问题……”说到这里就断了,究其本质还是对布谷鸟过滤器不太熟悉。所以想借着这个契机,和大家简单聊聊布谷鸟过滤器,以及——布谷鸟过滤器真的是比布隆过滤器更好的选择吗?
在布谷鸟之前:布隆过滤器的缺点与展望
在开讲布谷鸟过滤器之前,我想先简单回顾一下布隆过滤器。
布隆过滤器(Bloom Filter)是一种特殊的数据结构,其本质是一个位数组和若干个哈希函数的组合。在元素存入布隆过滤器时,首先要对元素进行哈希运算,得到哈希值hash 1、hash 2、...、hash n ,然后将坐标为hash 1、hash 2、...、hash n的位标记成 1 以实现元素的存储。当需要判断元素是否存在于布隆过滤器中时,也是基于同样的操作,只需要先计算出哈希值,再判断哈希值对应的位是否被标记成 1,就能判断元素是否存在于布隆过滤器中。布隆过滤器有一个很明显的好处,就是我们只需要进行 n 次运算就能判断出元素是否存在于布隆过滤器中,其时间复杂度相较于其他数据类型而言有明显的改善,但是布隆过滤器有两个明显的缺点,第一个缺点就是布隆过滤器的误判,由于可能存在哈希碰撞的问题,不同的元素通过哈希函数计算之后得到了相同的哈希值,进而可能会出现 “元素本来不存在于布隆过滤器,但布隆过滤器却判断其存在” 的情况,也就是我们常说的 “误判”;第二个缺点就是布隆过滤器无法删除元素,因为布隆过滤器本质上存储的是元素经过哈希运算之后得到的哈希值对应的bit值而不是元素本身,所以对于布隆过滤器而言,删除元素本来就是一件很不现实的事情——毕竟如果草率地将哈希值对应的bit值标记为 0 来表示元素被删除,就会出现其他元素被布隆过滤器“误判”为“不存在”的情况,因为其他元素计算出来的哈希值和被删除元素计算出来的哈希值很有可能是相同的,如果直接将bit值标记为 0,那么布隆过滤器需要判断其他元素是否存在的时候就会因为这个bit值被标记成了0而将其他元素误判为“不存在”。
基于这些问题,我们提出了一个展望:我们希望能够设计出一个新的数据结构,这个数据结构继承了布隆过滤器的“优良传统”,也就是能够实现快速判断元素是否存在,也摈弃了布隆过滤器的“缺陷”,也就是误判和无法删除元素的问题。介于此,布谷鸟过滤器由此诞生。
布谷鸟过滤器:鸠占鹊巢
2014年,来自CMU、Harvard 和 Intel 的团队基于布谷鸟哈希算法设计出了一个新的数据结构,他们将其命名为“Cuckoo Filter”,中文译名即为“布谷鸟过滤器”。在团队发表的文章 “Cuckoo Filter: Practically Better Than Bloom” 的引言部分,简单提到了布谷鸟过滤器和布隆过滤器的对比,颇有一种“碰瓷”的意味。
We propose a new data structure called the cuckoo filter that can replace Bloom filters for approximate set membership tests. Cuckoo filters support adding and removing items dynamically while achieving even higher performance than Bloom filters. For applications that store many items and target moderately low false positive rates, cuckoo filters have lower space overhead than space-optimized Bloom filters. Our experimental results also show that cuckoo filters outperform previous data structures that extend Bloom filters to support deletions substantially in both time and space.
文章提到,布谷鸟过滤器相较于布隆过滤器,有以下几点明显的优势:
- 支持动态地添加和删除元素 (It supports adding and removing items dynamically)
- 比传统的布隆过滤器有更好的查询性能,即使布谷鸟过滤器即将被填满 (It provides higher lookup performance than traditional Bloom filters, even when close to full)
- 比其他替代方案(如 Quotient Filter)更容易实现 (It is easier to implement than alternatives such as the quotient filter)
- 如果误判率小于 3% ,那么它的空间占用比布隆过滤器更小 (It uses less space than Bloom filters in many practical applications, if the target false positive rate is less than 3%)
布谷鸟过滤器是基于布谷鸟哈希算法实现的,所以先介绍布谷鸟哈希算法。
布谷鸟哈希算法的特性可以用一个成语来概括,那就是“鸠占鹊巢”,也就是本小节的标题。布谷鸟哈希算法是使用两个哈希函数对同一个元素进行哈希运算,得到两个哈希值,进而得到在桶中存储的位置,此时
- 若两个位置都为空,则随机选择一个位置将元素放入;
- 若只有一个位置为空,则将元素放入这个空位置;
- 若两个位置都不为空,则将两个位置上的元素随机“踢”走一个,新元素占据其位置,被“踢”走的元素通过哈希运算重新寻找新的位置。

当存入布谷鸟过滤器的元素足够多时,这种“踢出”已有元素的情况就会越来越频繁,所以一般会设置一个 踢出阈值,当超出这个阈值,布谷鸟过滤器就会进行扩容,减少频繁地“踢出元素”对插入性能的影响。
而布谷鸟过滤器本身的插入过程,具体可以如下图所示。

图中的 (a) 和 (b) 展示了布谷鸟过滤器的插入过程,和布谷鸟哈希算法的插入流程基本同理,因此不再赘述。基本的布谷鸟过滤器由两个或多个哈希函数构成,布谷鸟过滤器的哈希表的基本单位又称为“条目” (entry) ,每个条目存储元素的 “指纹” (fingerprint),指纹指的是哈希函数生成的 n 位比特位,一般根据能接受的最大误判率来设置。具体的布谷鸟过滤器的哈希表如图 © 所示。
布谷鸟过滤器的插入
与传统的布谷鸟哈希不同,布谷鸟过滤器采用了两个并不独立的哈希函数
其中, 是指待插入的元素, 是指元素的指纹, 即为计算出来的两个哈希值。具体来讲,第一个桶的索引是通过某个哈希函数计算出来,第二个是使用第一个索引和 指纹的哈希 做了一个异或操作,由于异或运算的特性,所以我们可以通过当前桶的索引 和存储在桶中的指纹 计算出备用桶的索引。 计算指纹 的哈希这一步是不是冗余的呢?并不是。因为指纹只是 key 映射出来的少量bit位置,假如不进行哈希操作,那么计算出来的备用位置和 差别很小,例如采用8位的指纹时,如果直接计算 ,那么最多改变 的低八位,也就是在数值上最多相差256,不利于均匀分配。
布谷鸟过滤器的查找
布谷鸟过滤器的查找也很简单。根据上述提及的插入方法,只需要用同样的方式计算出两个桶的位置和指纹 ,再判断对应的桶内是否能够和指纹 匹配,如果可以匹配,则认为元素存在,返回 true,反之则不存在,返回 false。
布谷鸟过滤器的删除
布隆过滤器不能实现删除元素的功能,如果要选择删除元素就必须重建布隆过滤器。布谷鸟过滤器则实现了删除功能,只需要从哈希表中删除对应的指纹和对应的项,即可实现删除。具体来讲,只需要在给定的两个候选桶中检查是否有匹配的指纹,如果有则直接删除匹配指纹的一个副本
没有银弹
布谷鸟过滤器真的完美吗?它真的能成为布隆过滤器的“替代品”吗?
软件工程领域有一个相当知名的说法,“There is no single development, in either technology or management technique, which by itself promises even one order of magnitude improvement within a decade in productivity, in reliability, in simplicity.”,用一句话总结就是,“No silver bullet”,没有银弹。
正如这个子标题,我想表达的是,布谷鸟过滤器也有自己的缺陷,而且它并不是布隆过滤器的替代品。
- 布谷鸟过滤器的删除功能并不完美,存在误删的可能性。由于删除的时候只是删除了一份指纹副本,不能判断这个副本属于被删除的
key的指纹。 - 插入时间复杂度比较高。随着已插入元素的增多,“踢出”元素的情况会越来越频繁,对于被“踢出”的元素而言,需要重新计算其索引,提高了插入时间复杂度,但总体来看,插入的时间复杂度还是维持在较低的水平。
- 存储空间必须为2的倍数,空间利用率较低。
- 对于同一个元素,布谷鸟过滤器最多可以插入 次,这里的 是指哈希函数的个数, 是指桶的尺寸。如果布谷鸟过滤器支持删除,则必须存储同一项的多个副本。 插入同一项 次将导致插入失败。 这类似于计数布隆过滤器,其中重复插入会导致计数器溢出。
介于此,我个人认为,布谷鸟过滤器是布隆过滤器的一个 “上位”替代,它实现了删除功能,也解决了布隆过滤器存在的误判问题,但是布谷鸟过滤器本身存在一些缺陷,所以它并不是完美的,也没法成为布隆过滤器的“替代品”。实际情况是,布隆过滤器的使用场景依然广泛,布隆过滤器也没有完全被布谷鸟过滤器所替代。
与其他过滤器的比较
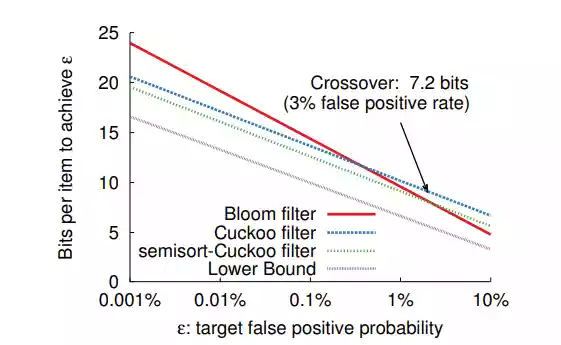
上图是布隆过滤器、布谷鸟过滤器和其他过滤器在误判率和元素空间成本上的比较。由图可知,布谷鸟过滤器在空间成本上比布隆过滤器更加出色,存储空间会更小。
布谷鸟过滤器的实现
因为笔者擅长使用Java,所以这里给出了布谷鸟过滤器Java版的实现,仅供读者参考。C++版本的实现在布谷鸟过滤器的 Github仓库 已有提供,其他版本的布谷鸟过滤器可以在 Github 上自行查找。
import java.util.Random; |
结语
在这篇博客中,我们简单地回顾了一下布隆过滤器,在了解了布隆过滤器的优点和缺点的基础上,我们又进一步引入了布谷鸟过滤器,布谷鸟过滤器较布隆过滤器有四点明显优势:
- 实现了元素的动态删除
- 查询性能更好
- 不存在误判的情况
- 空间占用的表现更加出色
但是布谷鸟过滤器也有明显的缺点,例如布谷鸟过滤器的空间利用率较低,布谷鸟过滤器的删除功能可能会导致误删等。实际开发场景下,布谷鸟过滤器也没有完全替代布隆过滤器,具体的选择要根据具体的业务场景来判断,选择合适的数据结构来满足开发需求。



