publicvoidsolve(char[][] board) { if (board == null || board.length == 0) { return; } row = board.length; col = board[0].length; for (inti=0; i < row; i++) { dfs(board, i, 0); dfs(board, i, col - 1); } for (inti=1; i < col - 1; i++) { dfs(board, 0, i); dfs(board, row - 1, i); } for (inti=0; i < row; i++) { for (intj=0; j < col; j++) { if (board[i][j] == 'A') { board[i][j] = 'O'; } elseif (board[i][j] == 'O') { board[i][j] = 'X'; } } } }
privatevoiddfs(char[][] board, int x, int y) { if (x < 0 || x >= row || y < 0 || y >= col || board[x][y] != 'O') { return; } board[x][y] = 'A'; dfs(board, x + 1, y); dfs(board, x - 1, y); dfs(board, x, y + 1); dfs(board, x, y - 1); } }
/* // Definition for a Node. class Node { public int val; public List<Node> neighbors; public Node() { val = 0; neighbors = new ArrayList<Node>(); } public Node(int _val) { val = _val; neighbors = new ArrayList<Node>(); } public Node(int _val, ArrayList<Node> _neighbors) { val = _val; neighbors = _neighbors; } } */
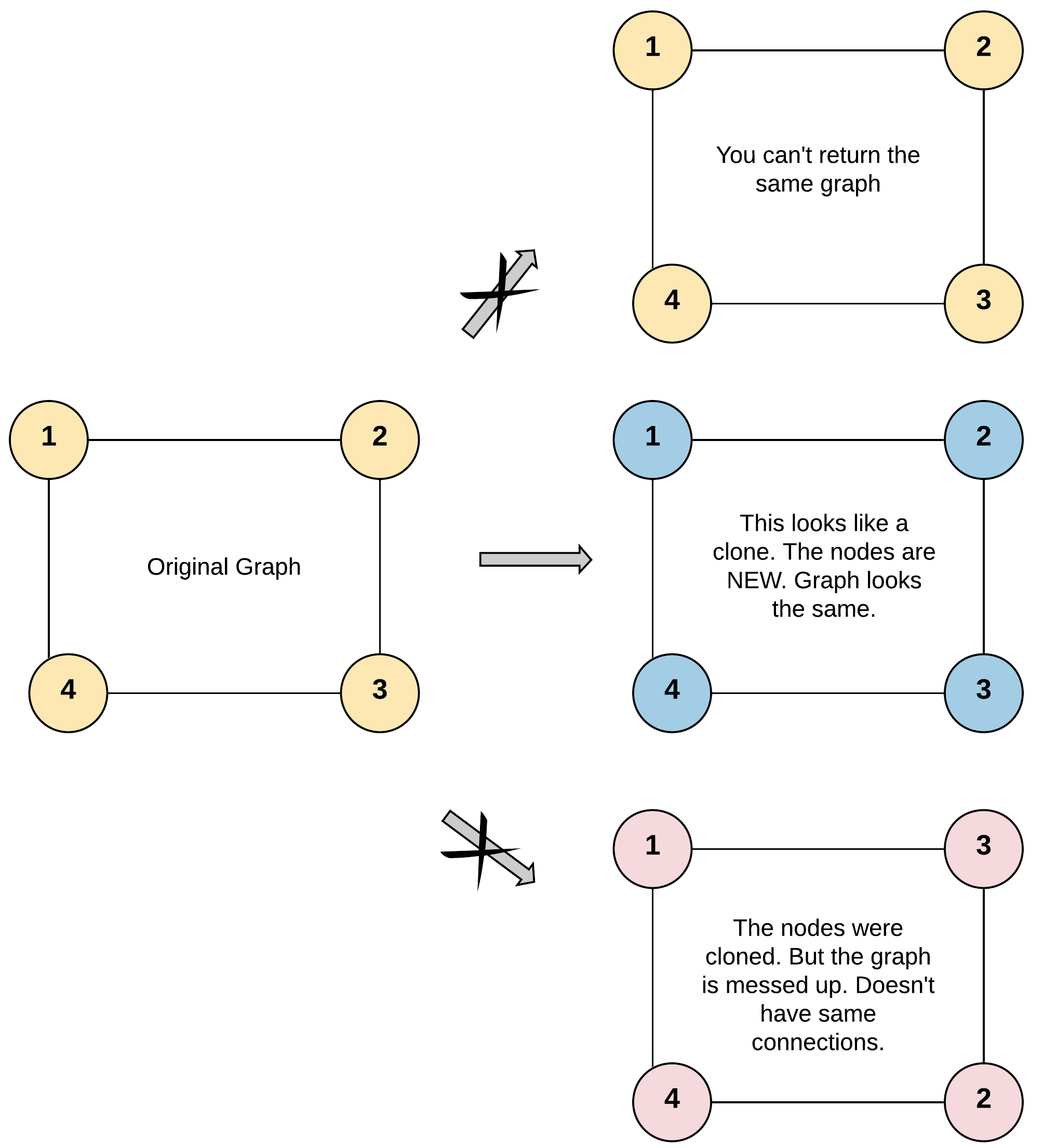
classSolution { private HashMap<Node, Node> vis = newHashMap<>();
public Node cloneGraph(Node node) { if (node == null) { return node; } if (vis.containsKey(node)) { return vis.get(node); } NodecloneNode=newNode(node.val, newArrayList<>()); vis.put(node, cloneNode); for (Node neighbor : node.neighbors) { cloneNode.neighbors.add(cloneGraph(neighbor)); } return cloneNode; } }